Achieving Continuous Uptime: The Mechanics of Zero Downtime Deployments
Discover the inner workings of zero downtime deployments, a crucial approach for maintaining uninterrupted service, even during significant updates or migrations.
Vayqube Team
Author
Introduction to Zero Downtime Deployments
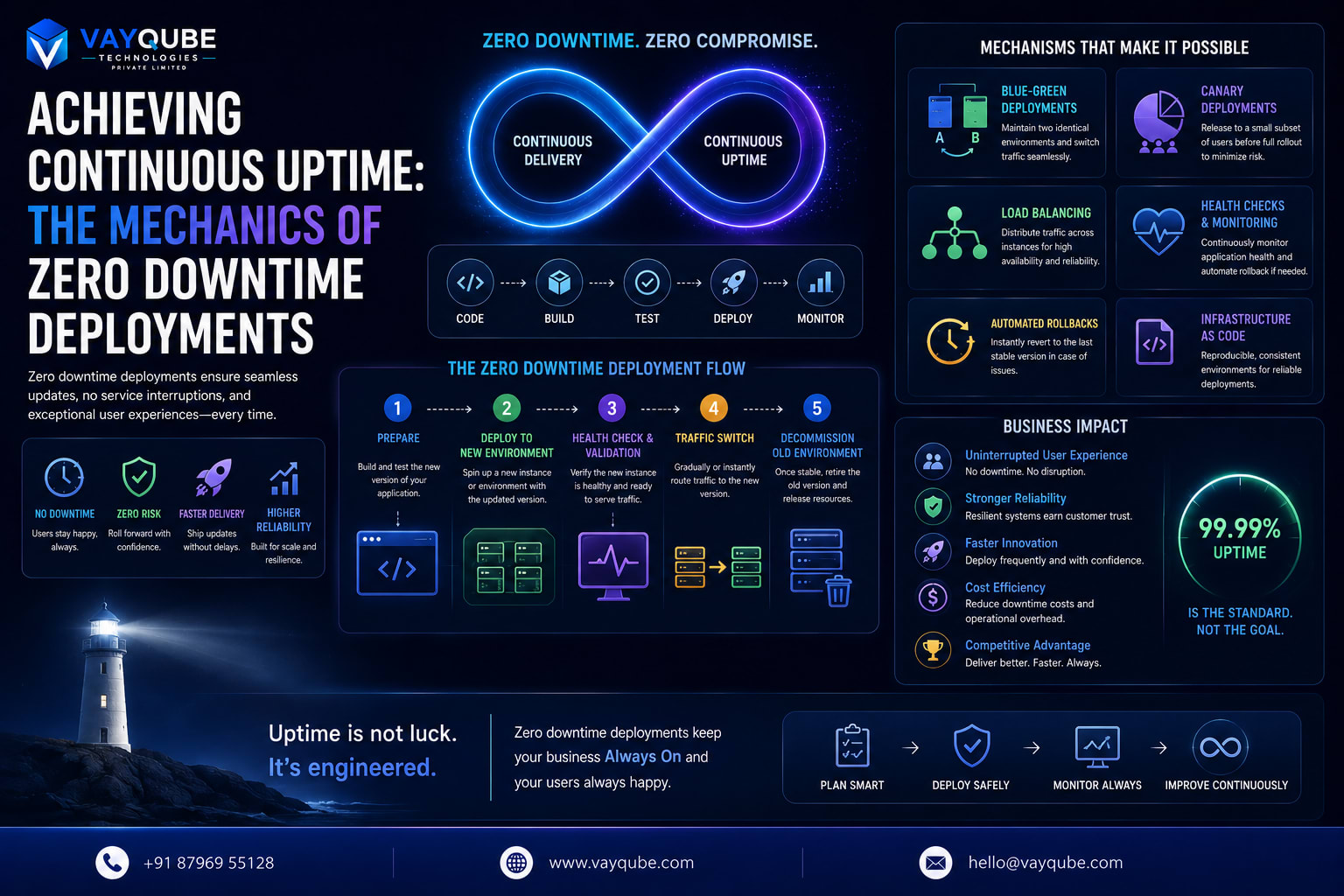
Zero downtime deployments refer to the process of updating or deploying new versions of an application without interrupting its service, ensuring that users can access it continuously. This approach has become crucial in modern applications, where even brief periods of downtime can result in significant losses in terms of revenue, customer satisfaction, and reputation.
The Importance of Continuous Uptime
Continuous uptime is vital for businesses that rely heavily on their online presence. Downtime can lead to a loss of customer trust, decreased sales, and a competitive disadvantage. In today's fast-paced digital landscape, users expect applications and services to be available 24/7, making zero downtime deployments a key strategy for maintaining a competitive edge.
Key benefits of achieving continuous uptime include:
- Enhanced user experience through uninterrupted service
- Protection of revenue streams by minimizing losses due to downtime
- Improved brand reputation and customer loyalty
- Ability to deploy updates and new features without disrupting service, leading to faster iteration and innovation
Real-World Implications
In real-world scenarios, the importance of continuous uptime can be seen in various industries. For instance, e-commerce platforms cannot afford downtime during peak shopping seasons, as it would lead to lost sales and revenue. Similarly, financial services and healthcare applications require high uptime to ensure the continuity of critical services. Achieving zero downtime deployments is, therefore, not just a technical goal but a business imperative for maintaining operational excellence and competitiveness.
Implementation Considerations
Implementing zero downtime deployments involves a combination of strategic planning, technological capabilities, and operational practices. This includes designing applications with scalability and redundancy in mind, leveraging cloud services and containerization, and adopting agile development methodologies that facilitate rapid and reliable deployments. By focusing on these aspects, organizations can ensure that their applications are always available, providing a solid foundation for business growth and customer satisfaction.
Financial Implications
The financial impact of downtime can be substantial, affecting a company's bottom line and overall revenue. According to various studies, the average cost of downtime for a business is around $5,600 per minute. This translates to approximately $336,000 per hour. For companies that rely heavily on their online presence, such as e-commerce platforms or online services, downtime can result in significant losses. In addition to direct revenue loss, downtime can also lead to indirect costs, including damage to brand reputation, loss of customer trust, and potential legal liabilities.
Customer Satisfaction and Retention
Customer satisfaction and retention are also critical aspects to consider when evaluating the importance of continuous uptime. In today's digital age, customers expect seamless and uninterrupted access to online services. Downtime can lead to frustration, disappointment, and ultimately, a loss of loyalty. A study found that 80% of customers would switch to a competitor after experiencing poor service, including downtime. Furthermore, acquiring new customers can be up to five times more expensive than retaining existing ones. Therefore, ensuring continuous uptime is essential for maintaining customer satisfaction and loyalty.
Competitive Advantage
Achieving continuous uptime can also provide a significant competitive advantage. In a market where downtime is common, companies that can guarantee uninterrupted service can differentiate themselves and attract customers seeking reliability. This is particularly important in industries where mission-critical applications are used, such as healthcare, finance, or emergency services. By investing in zero-downtime deployments, businesses can demonstrate their commitment to reliability, security, and customer satisfaction, ultimately gaining a competitive edge in the market. Some key benefits of continuous uptime include:
- Increased customer trust and loyalty
- Improved brand reputation
- Enhanced competitive advantage
- Reduced risk of financial losses due to downtime
- Increased operational efficiency and productivity
In real-world scenarios, companies that have successfully implemented zero-downtime deployments have seen significant improvements in their overall performance and customer satisfaction. For instance, a leading e-commerce platform was able to reduce its downtime by 90% after implementing a zero-downtime deployment strategy, resulting in a 25% increase in sales and a 30% increase in customer satisfaction. By prioritizing continuous uptime, businesses can reap numerous benefits that can have a lasting impact on their success and growth.
Core Architecture
To achieve continuous uptime, a robust core architecture is essential. This involves designing a system that can handle deployments without interrupting service.
Overview of Zero Downtime Deployment Strategies
Zero downtime deployment strategies focus on ensuring that users do not experience any interruption in service during the deployment of new versions of an application. This can be achieved through various techniques, including:
- Blue-green deployments, where two identical environments are maintained, and traffic is routed between them
- Rolling updates, where instances are updated one by one to minimize disruption
- Canary releases, where a new version is deployed to a small subset of users before rolling it out to the entire user base
Role of Load Balancers and Auto-Scaling
Load balancers play a critical role in zero downtime deployments by distributing traffic across multiple instances of an application. This ensures that no single instance is overwhelmed and becomes a single point of failure. Auto-scaling is also crucial, as it allows the system to dynamically adjust the number of instances based on demand, ensuring that there are always enough resources available to handle traffic.
Containerization and Orchestration Tools
Containerization tools, such as Docker, and orchestration tools, such as Kubernetes, are essential components of a zero downtime deployment architecture. Containerization allows applications to be packaged into portable, self-contained units that can be easily deployed and managed. Orchestration tools automate the deployment, scaling, and management of containers, ensuring that the system is always running at optimal levels. Some key benefits of using containerization and orchestration tools include:
- Improved resource utilization
- Increased deployment speed
- Enhanced scalability and reliability
- Simplified management and monitoring
By leveraging these technologies and strategies, organizations can build a robust core architecture that supports zero downtime deployments and ensures continuous uptime for their applications.
Implementation Considerations
When implementing a zero downtime deployment architecture, there are several key considerations to keep in mind. These include:
- Ensuring that the system is designed to handle failures and can automatically recover from them
- Implementing monitoring and logging tools to provide visibility into system performance and issues
- Developing a robust testing strategy to ensure that deployments do not introduce errors or downtime
- Continuously evaluating and improving the system to ensure it remains scalable, reliable, and efficient.
By carefully considering these factors and designing a robust core architecture, organizations can achieve continuous uptime and ensure that their applications are always available to users.
Business Benefits
The implementation of zero downtime deployments has a significant impact on businesses, leading to improved system reliability, increased agility, and enhanced customer experience.
Improved System Reliability
A reliable system is crucial for businesses to maintain customer trust and ensure continuous operation. Zero downtime deployments minimize the risk of system failures, reducing the likelihood of lost sales, damaged reputation, and decreased customer satisfaction. By ensuring that the system remains operational during deployments, businesses can maintain a high level of reliability, leading to increased customer loyalty and retention.
Increased Agility and Faster Time-to-Market
The ability to deploy new features and updates without downtime enables businesses to respond quickly to changing market conditions and customer needs. This increased agility allows companies to innovate faster, reducing the time-to-market for new products and services. With zero downtime deployments, businesses can:
- Deploy new features and updates more frequently
- Respond quickly to customer feedback and market trends
- Stay ahead of the competition with faster innovation
Enhanced Customer Experience
A seamless and uninterrupted customer experience is essential for building trust and driving business growth. Zero downtime deployments ensure that customers can access services and applications without interruption, leading to increased satisfaction and loyalty. By providing a reliable and always-on experience, businesses can:
- Increase customer engagement and retention
- Improve customer satisfaction and loyalty
- Drive business growth through positive word-of-mouth and online reviews
The benefits of zero downtime deployments are clear, and businesses that implement this approach can gain a competitive edge in the market. By prioritizing system reliability, agility, and customer experience, companies can drive growth, innovation, and success in today's fast-paced digital landscape.
Real-World Examples
Many businesses have successfully implemented zero downtime deployments, achieving significant benefits and improvements in their operations. For example, companies like Netflix and Amazon have developed sophisticated deployment strategies that enable them to release new features and updates without interrupting their services. These examples demonstrate the potential of zero downtime deployments to drive business success and growth.
Production Considerations
When implementing zero downtime deployments, businesses must consider several production factors, including the complexity of their systems, the frequency of deployments, and the potential impact on customers. By carefully evaluating these factors and developing a tailored deployment strategy, companies can ensure a smooth and successful transition to zero downtime deployments.
Scalability
To achieve continuous uptime, scalability is a critical component. It enables systems to handle increased traffic and demand without compromising performance. There are several approaches to scalability, each with its own benefits and considerations.
Horizontal Scaling and Resource Allocation
Horizontal scaling involves adding more resources, such as servers or containers, to distribute the workload. This approach allows for efficient use of resources and can be easily automated. Key considerations include:
- Resource allocation: ensuring that resources are allocated efficiently to handle traffic demand
- Load balancing: distributing traffic across multiple resources to prevent bottlenecks
- Automation: using automation tools to scale resources up or down as needed
Dynamic Scaling Based on Traffic Demand
Dynamic scaling takes horizontal scaling a step further by automatically adjusting resources based on real-time traffic demand. This approach ensures that resources are allocated optimally, reducing waste and improving responsiveness. Benefits include:
- Improved resource utilization
- Enhanced responsiveness to changing traffic patterns
- Reduced operational overhead
Cloud-Native Services for Scalability
Cloud-native services, such as serverless computing and containerization, offer scalable and on-demand resources. These services provide:
- Scalability on demand: resources are allocated and deallocated as needed
- Reduced operational overhead: cloud providers manage underlying infrastructure
- Improved reliability: built-in redundancy and failover capabilities
Effective scalability strategies require careful consideration of traffic patterns, resource allocation, and automation. By leveraging horizontal scaling, dynamic scaling, and cloud-native services, organizations can build highly scalable systems that support continuous uptime and exceptional user experiences.
When implementing scalable systems, it's essential to consider production readiness and real-world use cases. This includes:
- Testing scalability under various traffic scenarios
- Monitoring performance and adjusting resources accordingly
- Ensuring seamless integration with existing infrastructure and applications
By prioritizing scalability and implementing effective strategies, organizations can ensure their systems are always available and performing optimally, even under extreme traffic conditions.
Implementation Challenges
Implementing zero downtime deployments is a complex task that requires careful consideration of several factors. One of the primary challenges is the complexity of deployment processes.
Deployment Process Complexity
The deployment process involves multiple steps, including building, testing, and deploying code changes. Each step must be executed flawlessly to ensure a seamless transition to the new version. However, the complexity of these processes can lead to errors, which can cause downtime or data inconsistencies. To mitigate this risk, it's essential to automate as much of the deployment process as possible, using tools like continuous integration and continuous deployment (CI/CD) pipelines.
Database Schema Changes and Data Consistency
Database schema changes and data consistency are also significant challenges in zero downtime deployments. When making changes to the database schema, it's crucial to ensure that the new schema is compatible with the existing data. This can be achieved by using techniques like backward compatibility, where the new schema is designed to work with the existing data. Additionally, data consistency must be maintained across the deployment process, which can be ensured by using transactions or locking mechanisms to prevent data corruption.
Rollback Strategies and Error Handling
Rollback strategies and error handling are critical components of zero downtime deployments. In the event of an error or failure during deployment, it's essential to have a rollback strategy in place to quickly revert to the previous version. This can be achieved by maintaining a backup of the previous version and using automated scripts to roll back to that version. Error handling is also crucial, as it enables the system to detect and respond to errors in real-time, minimizing the impact of downtime. Some common error handling strategies include:
- Implementing retry mechanisms to handle transient errors
- Using circuit breakers to prevent cascading failures
- Maintaining a queue of pending requests to ensure that no requests are lost during deployment
By addressing these implementation challenges, organizations can ensure a smooth and seamless deployment process, minimizing the risk of downtime and data inconsistencies. This, in turn, can help to improve the overall reliability and availability of their systems, leading to increased customer satisfaction and loyalty.
Real-World Examples
Real-world examples of zero downtime deployments can be seen in companies like Netflix, Amazon, and Google, which have implemented sophisticated deployment systems to ensure high availability and reliability. These companies use a combination of automation, monitoring, and error handling to ensure that their systems are always available, even during deployment. By studying these examples and implementing similar strategies, organizations can achieve continuous uptime and improve their overall system reliability.
Production Considerations
When implementing zero downtime deployments in production, it's essential to consider factors like scalability, performance, and security. The deployment process must be designed to scale with the organization's growth, ensuring that it can handle increasing traffic and user demand. Additionally, the deployment process must be optimized for performance, ensuring that it does not impact the system's responsiveness or throughput. Finally, security must be a top priority, ensuring that the deployment process is secure and that sensitive data is protected. By considering these production factors, organizations can ensure a smooth and successful deployment process.
Use Cases
Zero downtime deployments have numerous applications across various industries, where continuous uptime is crucial for business operations and customer satisfaction.
E-commerce and Retail Applications
E-commerce platforms and retail applications require high availability to ensure uninterrupted customer experiences. With zero downtime deployments, online stores can:
- Process transactions and orders without interruption
- Update product catalogs and inventory in real-time
- Implement security patches and updates without affecting customer access
- Scale to meet peak demand during sales and promotions
Financial Services and Banking
Financial institutions and banks rely on zero downtime deployments to maintain the integrity of their systems and ensure compliance with regulatory requirements. This includes:
- Processing transactions and account updates in real-time
- Implementing security measures to prevent fraud and data breaches
- Ensuring continuous access to online banking and mobile banking services
- Meeting strict regulatory requirements for system uptime and availability
Healthcare and Critical Infrastructure
Healthcare organizations and critical infrastructure providers require zero downtime deployments to ensure the continuity of life-saving services and critical operations. This includes:
- Maintaining access to electronic health records and medical systems
- Ensuring continuous operation of life-support systems and medical equipment
- Implementing security measures to protect sensitive patient data
- Meeting regulatory requirements for system uptime and availability in healthcare and critical infrastructure environments
The implementation of zero downtime deployments in these industries requires careful planning, precise execution, and ongoing monitoring to ensure continuous uptime and minimal disruption to business operations. By leveraging zero downtime deployments, organizations can improve customer satisfaction, reduce the risk of revenue loss, and maintain regulatory compliance.
In real-world scenarios, zero downtime deployments have been successfully implemented in various industries, resulting in significant improvements in system availability, customer satisfaction, and business continuity. For instance, a leading e-commerce platform implemented zero downtime deployments to ensure continuous uptime during peak sales periods, resulting in a significant increase in customer satisfaction and revenue. Similarly, a major financial institution implemented zero downtime deployments to maintain the integrity of their systems and ensure compliance with regulatory requirements, resulting in improved system availability and reduced risk of non-compliance.
The key to successful zero downtime deployments lies in the ability to balance the need for continuous uptime with the need for ongoing maintenance, updates, and improvements. By leveraging automation, monitoring, and precise execution, organizations can ensure continuous uptime and minimize disruption to business operations, resulting in improved customer satisfaction, reduced revenue loss, and improved regulatory compliance.
As organizations continue to rely on digital systems and infrastructure to drive business operations, the importance of zero downtime deployments will only continue to grow. By understanding the mechanics of zero downtime deployments and implementing them effectively, organizations can improve system availability, reduce risk, and drive business success.
The benefits of zero downtime deployments are clear, and the technology is available to support it. However, the implementation requires careful planning, execution, and ongoing monitoring to ensure continuous uptime and minimal disruption to business operations. By prioritizing zero downtime deployments, organizations can ensure continuous uptime, improve customer satisfaction, and drive business success in today's fast-paced digital landscape.
Best Practices
To achieve continuous uptime and zero downtime deployments, several best practices can be employed. These practices focus on ensuring that the system is thoroughly tested, monitored, and maintained to prevent any potential downtime.
Automated Testing and Validation
Automated testing and validation are crucial in ensuring that the system is functioning as expected. This involves:
- Implementing unit tests, integration tests, and end-to-end tests to cover all aspects of the system
- Using automated testing tools to run tests continuously, including during deployment
- Validating user input and expected outputs to prevent errors
- Conducting regular security audits and penetration testing to identify vulnerabilities
Monitoring and Logging Strategies
Monitoring and logging are essential in identifying potential issues before they cause downtime. This includes:
- Implementing monitoring tools to track system performance, errors, and exceptions
- Setting up logging mechanisms to capture and analyze system logs
- Using analytics tools to identify trends and patterns in system behavior
- Establishing alerting and notification systems to inform teams of potential issues
Continuous Integration and Delivery Pipelines
Continuous integration and delivery (CI/CD) pipelines are critical in ensuring that changes are properly tested, validated, and deployed without causing downtime. This involves:
- Implementing CI/CD tools to automate the build, test, and deployment process
- Using containerization and orchestration tools to manage and deploy applications
- Conducting regular reviews and updates of the CI/CD pipeline to ensure it remains effective
- Implementing rollbacks and backups to quickly recover in case of issues
By implementing these best practices, organizations can significantly reduce the risk of downtime and ensure continuous uptime, even during deployments. This requires careful planning, execution, and monitoring, but the benefits to the business and customers are well worth the effort.
Implementation Considerations
When implementing these best practices, organizations should consider their specific use cases, system architecture, and business requirements. This includes:
- Evaluating the trade-offs between automation, testing, and deployment speed
- Assessing the impact of monitoring and logging on system performance
- Determining the optimal CI/CD pipeline configuration for their applications
- Establishing clear communication and collaboration channels between development, operations, and quality assurance teams
Real-World Examples
Real-world examples of successful zero downtime deployments can be seen in companies such as Netflix, Amazon, and Google, which have implemented sophisticated CI/CD pipelines and monitoring systems to ensure continuous uptime. These companies have demonstrated that with careful planning, execution, and monitoring, it is possible to achieve zero downtime deployments and ensure continuous uptime, even in complex and distributed systems.
Production Readiness
To ensure production readiness, organizations should focus on:
- Conducting thorough testing and validation of the system
- Implementing monitoring and logging mechanisms to identify potential issues
- Establishing clear incident response and management processes
- Continuously reviewing and updating the system to ensure it remains secure, scalable, and reliable.
FAQ
To address common queries and provide clarity on the concept of zero downtime deployments, let's delve into some frequently asked questions and topics of interest.
Common Misconceptions About Zero Downtime Deployments
There are several misconceptions surrounding zero downtime deployments. Some of the most prevalent include:
- The belief that achieving zero downtime is impossible or highly impractical for most businesses.
- The notion that zero downtime deployments are only necessary for large-scale or critical infrastructure applications.
- The assumption that implementing zero downtime deployments will significantly increase costs without providing proportional benefits.
In reality, zero downtime deployments are achievable with the right strategy and technology. They are beneficial for any application where uptime is crucial, regardless of the business size. Moreover, while there may be initial investment costs, the long-term benefits of reduced downtime and increased user satisfaction can lead to significant financial gains.
Comparison with Traditional Deployment Methods
Traditional deployment methods often involve taking the application or service offline to perform updates or maintenance. This approach can lead to:
- Direct financial losses due to lost sales or revenue.
- Indirect losses through decreased customer satisfaction and potential long-term damage to the brand reputation.
- Increased operational complexity and risk, as maintenance windows can be narrow and stressful for IT teams.
In contrast, zero downtime deployments allow for seamless updates without interrupting service, providing a competitive edge in terms of reliability and user experience.
Future of Zero Downtime Deployments and Emerging Trends
The future of zero downtime deployments is closely tied to advancements in cloud computing, containerization, and automation technologies. Emerging trends include:
- The use of serverless architectures to further reduce the risk of downtime.
- The integration of artificial intelligence and machine learning to predict and prevent potential downtime causes.
- The adoption of edge computing to reduce latency and improve real-time application performance.
As technology continues to evolve, the barriers to implementing zero downtime deployments will decrease, making this capability more accessible to businesses of all sizes. The key to success will lie in the ability to adapt and leverage these emerging trends effectively.
Conclusion
Achieving continuous uptime is a critical aspect of modern SaaS applications, and zero downtime deployments are a key strategy for ensuring high availability. In this article, we have explored the mechanics of zero downtime deployments, including the core architecture, business benefits, scalability, implementation challenges, and best practices.
Summary of Key Takeaways
The key takeaways from this article include:
- Zero downtime deployments require a robust and scalable architecture
- Automation and orchestration are critical for successful deployments
- Monitoring and logging are essential for identifying and resolving issues
- Continuous testing and validation are necessary for ensuring application quality
- A culture of continuous improvement and learning is necessary for achieving continuous uptime
Actionable Steps for Implementing Zero Downtime Deployments
To implement zero downtime deployments, organizations can take the following steps:
- Assess their current architecture and identify areas for improvement
- Implement automation and orchestration tools, such as Kubernetes or Ansible
- Develop a comprehensive monitoring and logging strategy
- Implement continuous testing and validation, using tools such as Jenkins or CircleCI
- Foster a culture of continuous improvement and learning, using techniques such as retrospectives and blameless post-mortems
Future-Proofing Applications for Continuous Uptime
To future-proof their applications for continuous uptime, organizations should focus on building scalable and resilient architectures, using cloud-native technologies such as containers and serverless computing. They should also prioritize automation, orchestration, and monitoring, and foster a culture of continuous improvement and learning. By taking these steps, organizations can ensure that their applications are always available, and that they can respond quickly and effectively to changing business needs.
Some of the strategies for future-proofing include:
- Using microservices architecture to improve scalability and resilience
- Implementing service mesh technologies, such as Istio or Linkerd, to improve service discovery and communication
- Using cloud-native storage solutions, such as object storage or NoSQL databases, to improve data availability and durability
- Implementing artificial intelligence and machine learning technologies, such as predictive analytics or anomaly detection, to improve application monitoring and automation.
By prioritizing these strategies, organizations can build applications that are highly available, scalable, and resilient, and that can respond quickly and effectively to changing business needs.
Related Vayqube Resources
- Best Mobile App Development Company In New York
- Top Mobile App Development Company In New York
- Case Study Saas Platform Scaling
- Startups Building Ai Products Without Large Teams
- Best Mobile App Development Company In India
- Best Mobile App Development Company In Usa
Next Step
If your systems are struggling with scalability, automation, architecture complexity, or operational efficiency, it's time to modernize your infrastructure and workflows.
👉 Talk to a Vayqube solution architect and build systems designed for long-term production growth: